StockHero: an honest ensemble of five stock-forecasting models
Owning the brief on a five-model forecasting product and building it through Claude — where the real work was deciding what 'honest' had to mean before any number was allowed to ship.
By Renaud Yasin
- Machine Learning
- Ensemble Forecasting
- Microservices
- Full-Stack
- Built with Claude
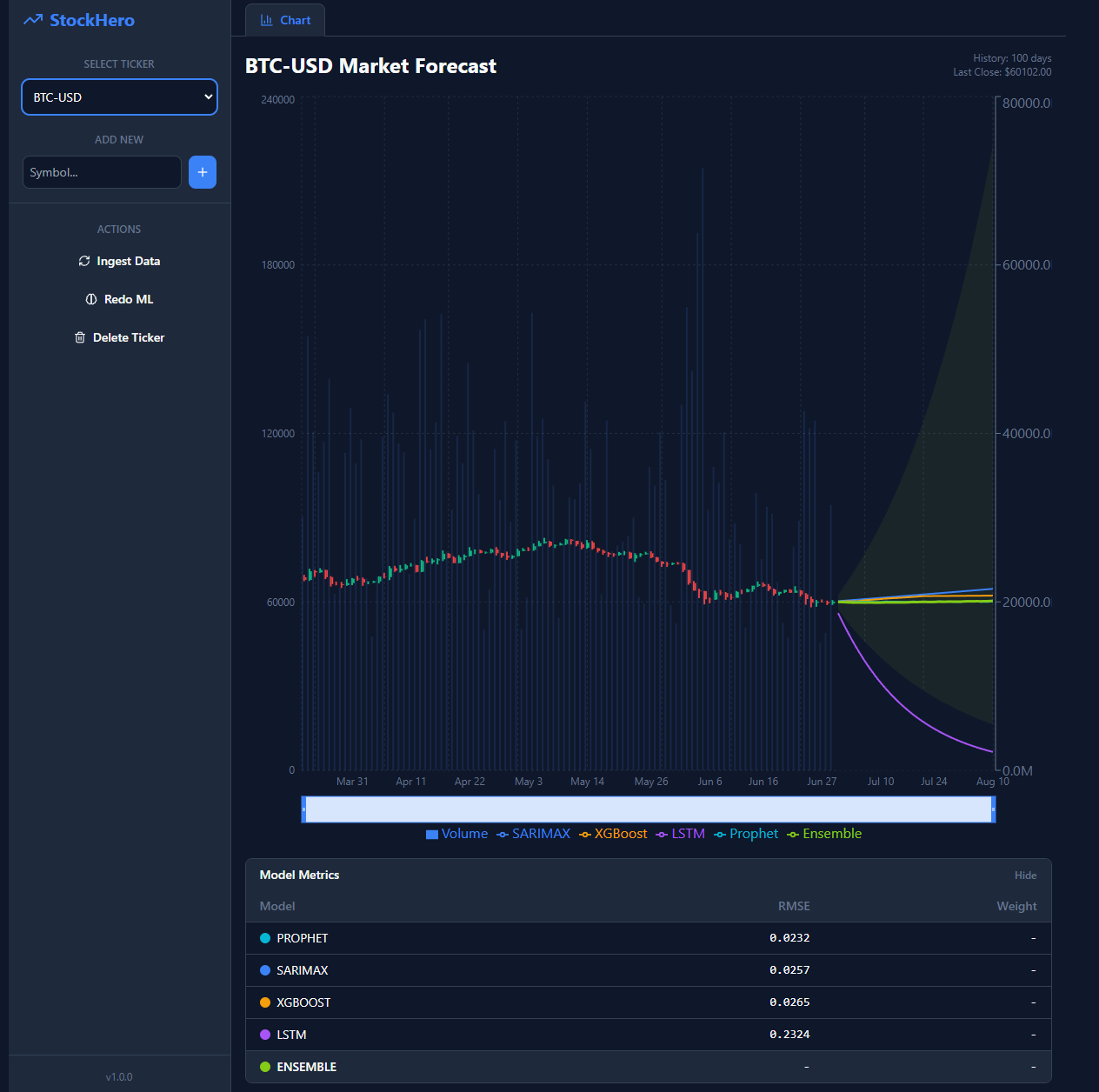
Most "stock predictor" projects stop at fitting one model and plotting a hopeful line. I set myself the opposite brief: several genuinely different models, an ensemble that combines them honestly, and enough engineering around it that I'd believe the numbers. As a product owner, my job was never to type every line — it was to decide what's worth building, set the guardrails, and steer it into existence through Claude. StockHero is the result — a small forecasting product I can run end to end, from pulling raw prices to rendering a confidence-aware forecast in the browser. The lessons that stuck were less about the models than about how you decide and hold the line when AI is doing the building.
The shape of the system
The product decision came first: this had to be a real system I could operate, not a notebook. That choice fixed the architecture — five services on an internal Docker network, fronted by a single Go API:
- Go API (Chi, pgx) — CRUD plus orchestration. Raw parameterized SQL, no ORM. It owns the async choreography: when ingestion finishes, it spawns background goroutines to retrain the affected tickers, so the front end never has to ask.
- Python ingestor — pulls daily OHLCV from yfinance and writes it to Postgres with delta-based UPSERTs, restarting from the last stored bar so partial trailing days get corrected rather than duplicated.
- Python ML trainer — fits SARIMAX, XGBoost, an LSTM, and Prophet, then an inverse-RMSE ensemble over the four. It also exposes seven portfolio-optimization strategies (pypfopt), and bounds heavy fitting with a semaphore so a multi-ticker fan-out can't OOM the box.
- React + Vite + Recharts — a hand-rolled candlestick chart (Recharts has no native one) with per-model forecast overlays and a shaded ensemble confidence band. Training status streams over SSE, with polling as a fallback.
- Postgres 15 — confidence intervals and full model lineage are first-class columns, not afterthoughts.
The product decision that did the load-bearing work
The interesting problem wasn't any single model — it was a product decision: build one honest yardstick first, and refuse to combine numbers that don't mean the same thing. Five different models will each happily report an error metric, and Claude will happily blend them into a confident-looking ensemble if the brief lets it — the model optimizes for the goal you actually set, not the one you meant. So the scarce thing was never the code. It was deciding, up front, that comparable had to come before combined, and then holding that line through every shortcut that would have flattered the result.
That decision became the spine of the build. Every model trains in returns space (not raw prices) for stationarity, and every one is scored the exact same way: a chronological holdout, in returns, with no leakage. SARIMAX refits on the train slice instead of reusing cheap in-sample residuals (which would have flattered it and over-weighted it in the blend). The LSTM's scaler is fit on the training split only. XGBoost re-engineers its features from the evolving predicted series at each forecast step rather than freezing them. Only because the error metric means the same thing for all four does inverse-RMSE weighting actually produce an ensemble I trust — and the same holdout residuals drive the 80% p10/p90 bands. None of that is exotic engineering; it's the product owner's refusal to ship a number I don't believe, turned into machinery the AI has to pass through.
Building it through Claude, with judgment in the loop
I treated it like real software, not a notebook, and that's exactly where building through AI earns its keep. Every fire-and-forget goroutine starts with a panic recover so one bad job can't take the process down; the stack is hardened (non-root containers, the database bound to localhost, internal-only services, optional bearer auth, per-IP rate limiting). And then the part I'd point to first: I ran a multi-agent code review that surfaced 93 findings, adversarially verified and tracked to closure, with tests across every service. That's the whole job in one beat — Claude can generate a five-service stack far faster than I could type it, but 93 findings only become a better product if someone owns which ones matter, presses on the ones that are real, and refuses to close them quietly. Setting that review loose and then exercising judgment over its output is the work, not a footnote to it.
What I'd carry forward
An ensemble is only as honest as its worst-measured member. The lesson that generalizes far past this project: build the single, leakage-free evaluation harness first, and make every model pass through it — the moment your metrics aren't comparable, any "combination" of them is just noise with extra steps. And the lesson this build taught me about my own job: when AI does the building, the product owner's leverage moves to defining "good" and holding the line on it. Claude will clear whatever bar you set across Go, Python, and TypeScript; choosing the right bar — comparable before combined — and refusing to lower it is the actual work, and still the fastest way I know to learn where a system's real seams are.