Parsing SEC EDGAR into clean profiles: a polite worker, a strict schema, and SSR pages
Owning the brief end to end as a product owner building through Claude — how far a genuinely free stack can go when you decide that trust and provenance, not features, are the product.
By Renaud Yasin
- Next.js
- Python
- Supabase
- Data pipeline
- Fintech
- Built with Claude
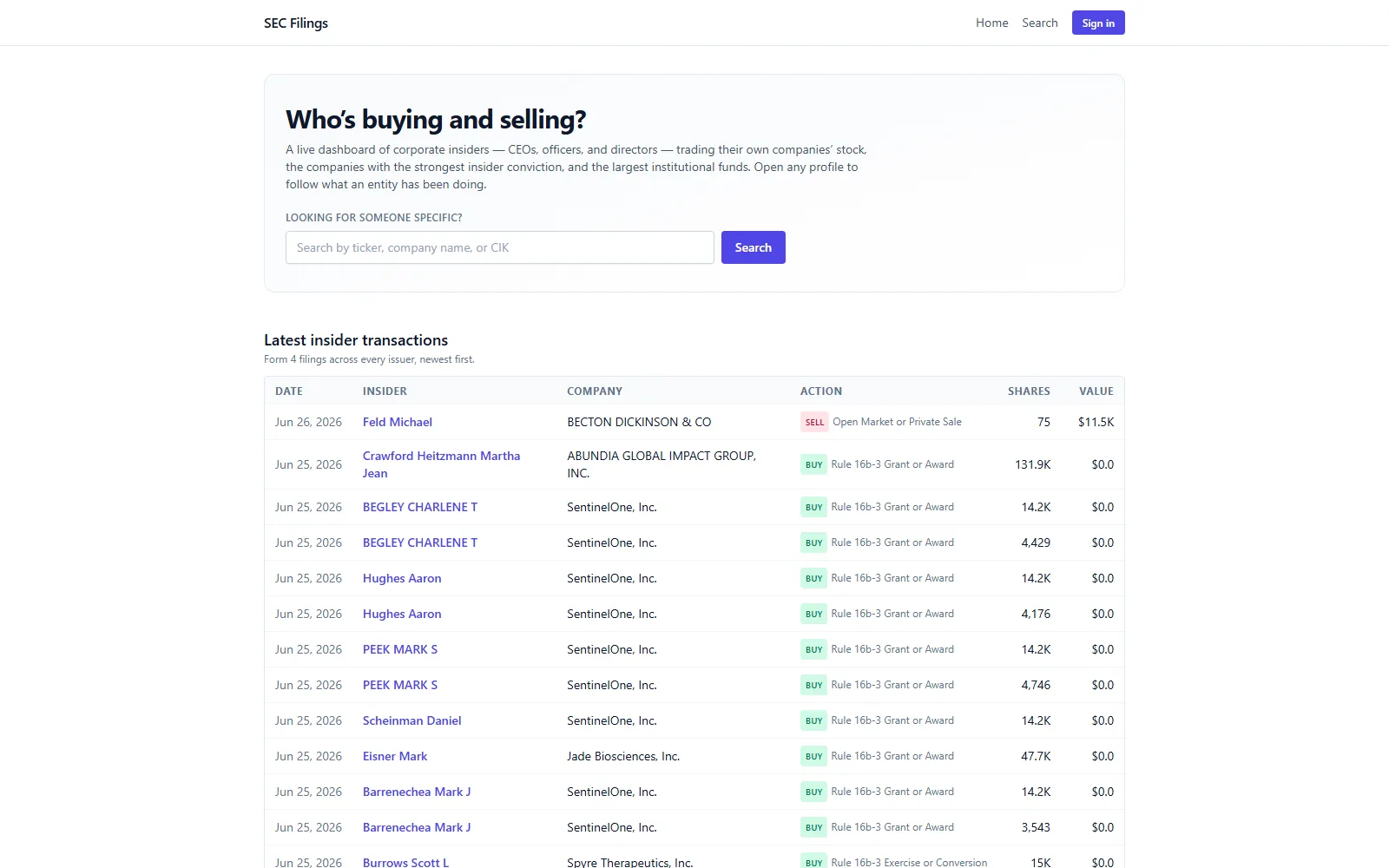
As a product owner, my job isn't to write every line — it's to decide what's worth building, set the brief and the guardrails, and steer it into existence through Claude. This project was a pointed version of that question: how far can a genuinely free stack go? SEC EDGAR holds everything a retail investor or journalist could want — who's buying their own company's stock, what the big funds hold, what risks a company flags this year that it didn't last — but it's published as raw XML, inline XBRL, and HTML almost nobody reads directly. The good consumer tools cost money. The brief I set: pull the filings myself, parse them properly, and serve clean, cited profiles, all inside the Vercel Hobby and Supabase Free tiers — and find out where that ceiling actually is by building straight through it.
The brief I set
The first decision wasn't technical — it was about who's allowed to write data, and that single rule shaped the whole monorepo. Three tracks:
worker/— a Python 3.12 package (secf) with a Typer CLI. It discovers new filings, fetches them, parses them, runs a calculation layer, and uploads. It's the only writer and holds the service-role key.supabase/— Postgres as the single source of truth, defined entirely by timestamped migrations, with Row-Level Security on the user-scoped tables.web/— a Next.js 15 / React 19 app that reads Supabase server-side with the anon key and renders the public profiles. No service-role key ever touches it.
Data flows one way: EDGAR → polite fetch → raw bytes archived to Storage → pure parsers → idempotent upsert → calc layer → SSR pages. I set the direction and the guardrails; Claude did the building, and the one-way contract is what let me reason about the whole thing without holding it all in my head.
Where my judgment was the load-bearing part
Being a polite guest is a product decision about whether this thing gets to exist at all. SEC bans IPs that misbehave, so an app that's rude to EDGAR isn't feature-poor — it's dead. That made rate limiting a trust requirement, and exactly the kind of constraint Claude will sail past unless the brief makes it a hard line. So every outbound request carries a contact User-Agent (enforced at startup) and passes through a single global token bucket capped at 10 requests/second — shared by dependency injection, because a per-module limiter silently multiplies the real rate. Conditional GETs (ETag / Last-Modified) and backoff-with-jitter on 429/5xx round it out.
Idempotency as an invariant, not a hope. If I'm asking people to trust these numbers, re-running the worker can't quietly change them. Filings are keyed by a UNIQUE accession number; child rows are delete-and-reinsert inside one transaction per filing. Re-ingesting any filing must yield identical row counts — and a chaos test kills the worker mid-ingest to prove no orphans survive.
Honest about the messy edges — out loud, as a feature. The temptation when AI is building is to let it paper over the ugly cases so the demo looks clean; I drew the opposite line. 13F filings give you a CUSIP, not a ticker, and there's no free CUSIP→ticker dataset — so a missing ticker is a first-class "unresolved" state that degrades gracefully rather than a parse failure. Congressional trade amounts are disclosed as ranges, so the UI shows ranges and labels any ranking "estimated," never a fabricated exact number.
What I'd carry forward
Two things. First, pure parsers — bytes in, dataclass out, no I/O — made the hardest code (inline XBRL, PDF transaction tables) trivially testable against golden fixtures; when Claude writes a parser whose only job is to transform bytes, I can verify it against a fixture instead of trusting it. Second, writing tests against external observables rather than the implementation's own output: idempotency, RLS isolation, and rate limits are verified at the database or HTTP boundary, so the tests survive refactors. The lesson that stuck about my own job: when AI does the building, the product owner's leverage is deciding what "trustworthy" has to mean and turning it into machinery the code can't slip past. The MVP is feature-complete and runs end-to-end on a Dockerized stack today; the next steps are purely operational — deploy it and point the worker's cron at live EDGAR.