RSS Feeder: a local-first marketing-intelligence engine on Go, pgvector, and on-device LLMs
A product owner's bet that brand intelligence could be useful and private at once — set the brief, drew the no-cloud line, and built it through Claude into a self-hosted pipeline that reads the news and answers with citations.
By Renaud Yasin
- Go
- Local LLMs
- RAG
- pgvector
- Microservices
- TDD
- Built with Claude
As a product owner, my job isn't to write every line — it's to decide what's worth building, set the brief and the guardrails, and steer it into existence through Claude. RSS Feeder was where I pressure-tested a specific bet: that I could have brand intelligence and privacy at the same time. I wanted to know what the news was saying about a set of brands and competitors — share of voice, sentiment, what's trending, which moves matter — without handing that question, and the reading list behind it, to a cloud service. So I set the brief, drew the line at no cloud, and built it through Claude: a self-hosted pipeline that polls hundreds of RSS/Atom feeds, reads the full articles, and runs everything through locally-hosted LLMs to produce a marketing-intelligence layer. Nothing leaves the machine, and there's no per-token bill.
The shape of the system
The first product decision was that local-first was the feature, not a compromise — and that fixed what the thing was allowed to be. Once "no byte leaves the machine" is non-negotiable, the architecture mostly falls out of it. I scoped it as decoupled stages rather than one monolith, because a system that has to survive flaky feeds and a model that can only run one head at a time needs seams I can reason about:
- Seven Go microservices — poller, extractor, embedder, enrich-dispatcher, analytics, an API, and a model gateway — connected by a Redis/asynq queue with retry, backoff, and a dead-letter archive. A slow or flaky site never stalls the pipeline.
- PostgreSQL 16 + pgvector is the single source of truth. Every derived artifact — embeddings, topic clusters, daily rollups, enrichment — is rebuildable from the raw articles via a
backfilltool. That was a deliberate call: keep one thing precious and let everything else be disposable. - A stateless Python FastAPI ML worker does the NLP: named-entity recognition, per-entity sentiment, abstractive summaries, and a controlled vocabulary of market signals (funding, launches, partnerships, hiring…).
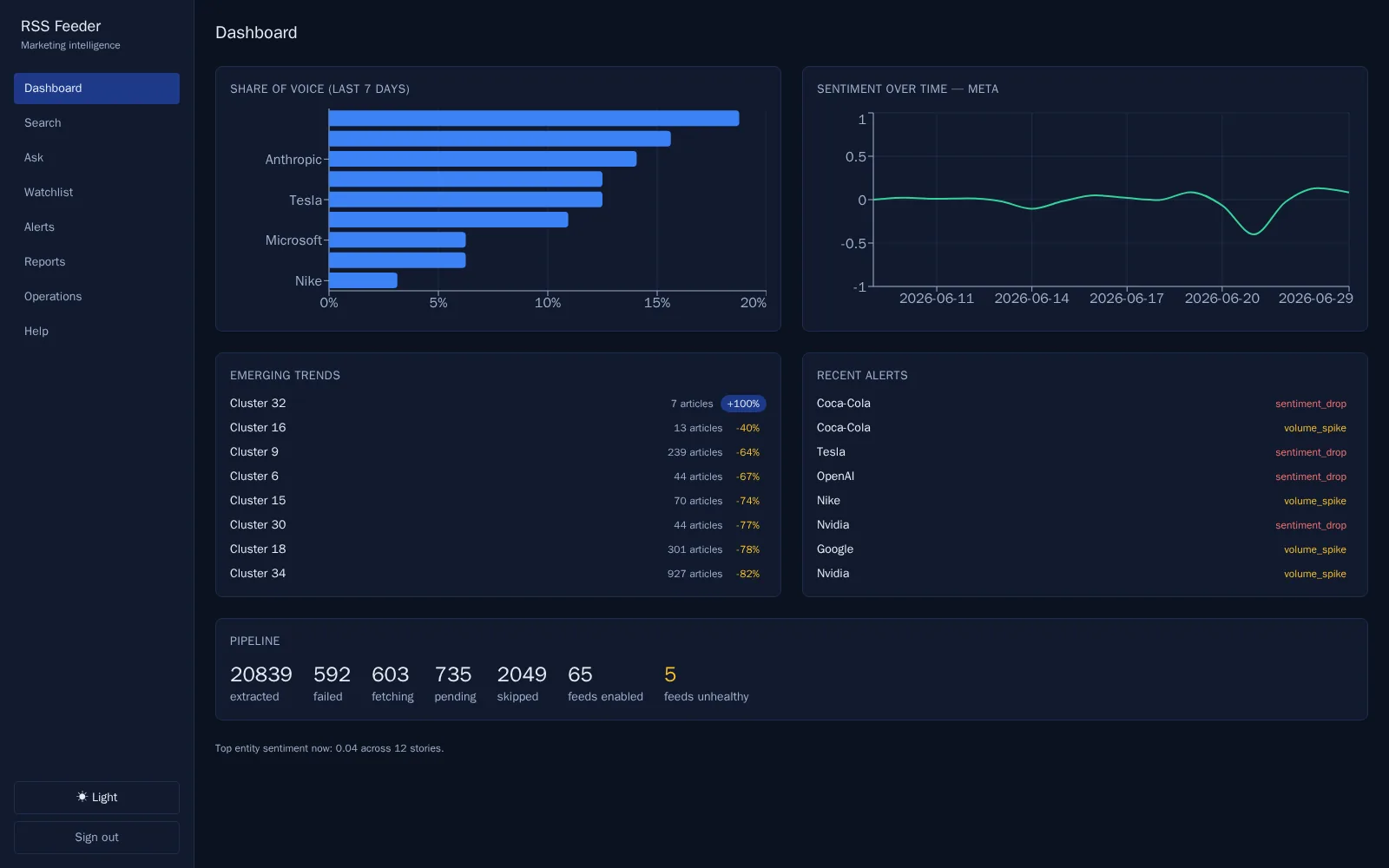
- A React + TypeScript + Tailwind + Recharts dashboard (the midnight-blue theme above) surfaces it all: hybrid search, an article reader, watchlists, alerts, scheduled reports, and a cited Q&A.
The flow: poll → extract full text (trafilatura, with a headless-Chrome fallback for JS-heavy pages) → embed (nomic-embed, 768-dim) → enrich (gpt-oss-20b) → cluster, roll up, and alert → serve. Search is hybrid — keyword full-text fused with vector similarity through reciprocal rank fusion — and there's a RAG endpoint that embeds your question, retrieves the top passages, and answers only from them with inline citations. That last rule — no sources, no claim — is a product decision about how much to trust a generation, not a feature I bolted on.
Where my judgment was the load-bearing part
The interesting constraint was hardware, and the interesting work was deciding what to do about it. I wanted real models, but one consumer machine can't hold the embedding model and a 20B chat model in RAM at once. The honest options were buy-bigger-hardware, rent-the-cloud, or make the constraint part of the design — and renting the cloud would have broken the one rule the whole project existed to honour. So the brief held, and through Claude I built llmgate: a serializing proxy in front of LM Studio that lets one model run at a time and evicts the outgoing model on every switch. The workers think they're talking to a normal OpenAI-compatible endpoint; the gateway quietly makes "only one model resident" true.
That decision was the spine of the project. A local 20B model is good enough to be useful and unreliable enough that you can't build on its word — so I refused to let a single generation become a fact in the database without the system having a way to doubt it. Building through Claude sharpened the point: the model clears whatever bar you set, so the scarce thing is deciding what "trustworthy" has to mean and holding the line on it. Choosing the right bar is the actual work, not the typing.
The other seam I had to own was the Go↔Python boundary. asynq is Go-only, and I didn't want to give up its reliability — so the queue stays in Go and the Python worker is a pure, stateless HTTP function. The Go dispatcher consumes a task, calls the worker, and persists entities, sentiment, summary, signals, and an audit row atomically in one transaction. Either the whole enrichment lands or none of it does; I won't ship half-written intelligence.
It's built strictly test-first: every functional requirement maps to a test, LLM calls are mocked with golden fixtures, and 80% coverage gates run in CI for both the Go and Python code. Those gates are the same instinct as the citations — machinery that makes the AI prove itself rather than a number I take on faith.
What I'd carry forward
Two things, and one about the job itself. First, single source of truth + everything rebuildable is a discipline that pays for itself — when a model or heuristic changes, I reset the derived data and let the workers refill it; no migrations of half-computed state. Second, the serializing-proxy pattern is a clean way to run "more model than fits" on modest hardware, and it generalizes well beyond this project. And the lesson that stuck about my own work: when AI is doing the building, the product owner's leverage is deciding what the thing is allowed to be — local-first, never trusting a raw generation, no claim without a source — and refusing to soften those rules when a looser one would have shipped faster. Local-first turned out not to be a compromise. It was the feature.