Chainsight: Forecasting Bitcoin On-Chain, Honestly
Owning a genuinely hard problem end to end as a product owner building through Claude — forecasting Bitcoin from my own full node, and making honesty about uncertainty the whole point.
By Renaud Yasin
- Machine Learning
- Bitcoin
- On-Chain Analytics
- Time Series
- Next.js
- Built with Claude
As a product owner, my job has never been to write every line — it's to decide what's worth building, set the brief and the guardrails, and steer it into existence. Chainsight was my test of how far that goes. Could I take a genuinely hard problem — forecasting Bitcoin end to end from on-chain data — and, working through Claude, own it from the brief and the guardrails all the way to a live, calibrated product? Not to trade it, but to see how every piece fits together: the node, the metrics, the models, the calibration, and the honesty about how little signal is really there.
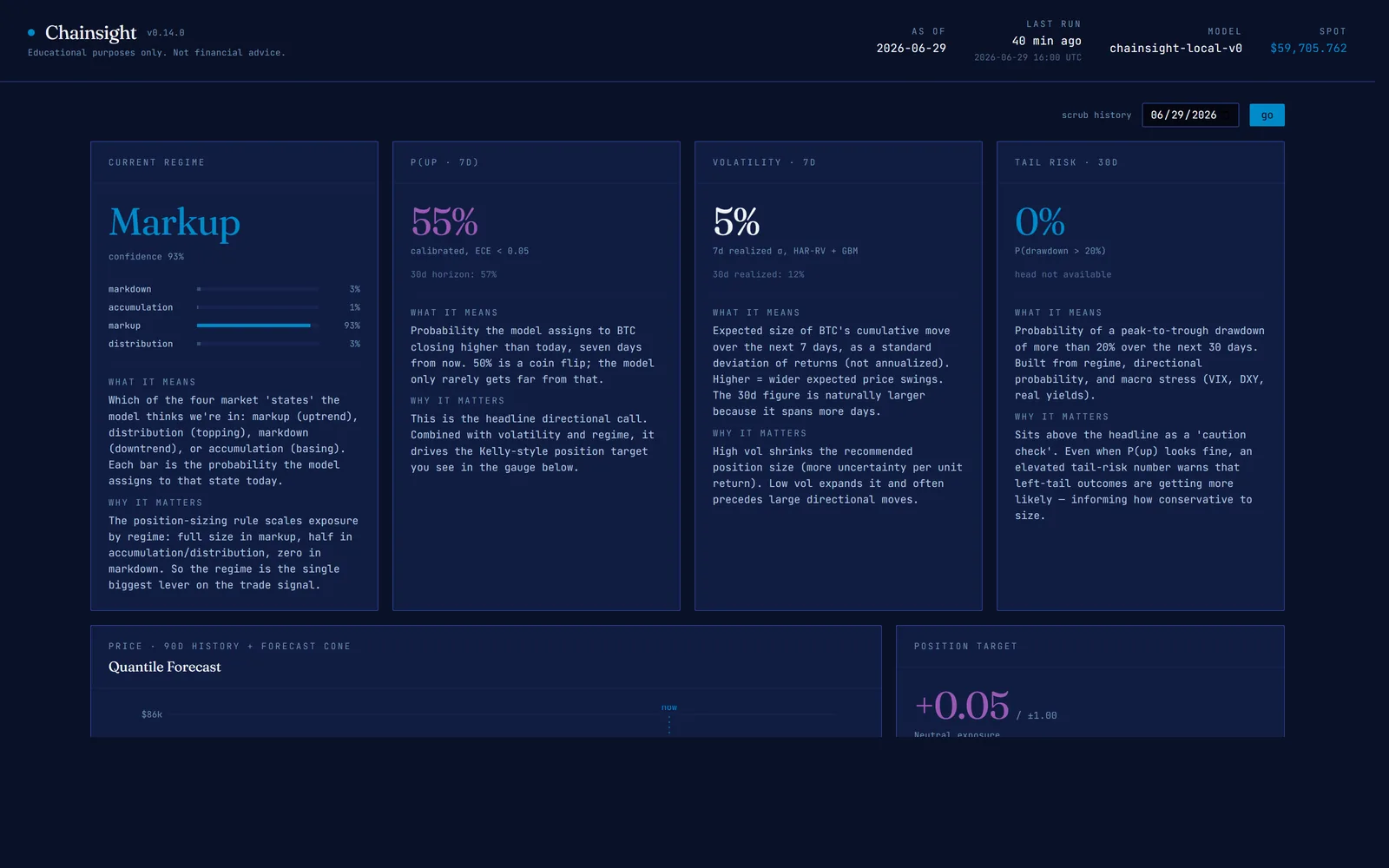
Chainsight is that system. Each day it forecasts five things — market regime, directional probability, volatility, a price range, and tail risk — and shows every number with its uncertainty and a plain-English explanation of what it means and why it matters. The lessons that stuck were less about the models than about how you think and decide when AI is doing the building.
The brief I set myself
Two rules did most of the work: no black boxes, and no bought data. That's a product decision before it's a technical one — it fixes what the thing is allowed to be, and most of the architecture falls out of it.
- On-chain metrics are computed locally from a Bitcoin Core full node. A set of Python indexers walk every block over JSON-RPC and maintain the full ~180-million-output UTXO set in SQLite, deriving MVRV, SOPR, supply-in-profit, coin-days-destroyed, dormancy, the Puell multiple, exchange flows and whale share — the kind of data you'd normally rent from Glassnode.
- Six model heads turn those features into forecasts: a LightGBM directional classifier, a HAR-RV + gradient-boosted volatility model, LightGBM quantile regressors for the price cone, a Gaussian-HMM-labelled regime classifier, a logistic tail-risk head, and a logistic meta-blender that calibrates the final probability.
- It runs offline every hour, writes predictions to Supabase, and a Next.js dashboard on Vercel reads them. No streaming, no live trading — a daily batch and a page that explains itself.
Where my judgment was the load-bearing part
The hard part wasn't the models — it was not fooling myself. And that turned out to be exactly where a product owner earns their keep when AI is doing the building. Financial time series leak the future through a dozen subtle doors, and a leaked feature will happily produce a beautiful, worthless backtest. Claude will happily write that beautiful, worthless backtest too, if the brief lets it — the model optimizes for the goal you actually set, not the one you meant. So the scarce thing was never the code. It was deciding, up front and in writing, what "honest" had to mean, and then refusing every shortcut that would have made the numbers look better than they were.
That decision became the spine of the project: point-in-time correctness. A store that only ever returns what was known on a given day. A 24-hour vendor lag baked into both training and inference. Features z-scored against an expanding 365-day-minimum window. López de Prado purged-and-embargoed cross-validation, so a label's future can't bleed into the fold that scores it. Every leakage test was written before the code it guards, across six first-class test categories (unit, leakage, golden, property, integration, acceptance). Seven model-quality gates are pinned in CI, so loosening one shows up as a visible diff rather than a quiet regression. None of that is exotic engineering — it's the product owner's refusal to ship a number I don't believe, turned into machinery the AI has to pass through.
That isn't a bug to fix; it's the finding. The blockchain shows settlement, not the price discovery happening on centralized exchanges, so there's a hard ceiling around 55–57% directional accuracy. Chainsight says so out loud and spends its effort on calibration — being right about how unsure it is — rather than pretending to alpha. When it says "55%," it means 55%, and the dashboard shows the price cone as the real output, with the median almost an afterthought.
Everything is auditable down to the feature. Each input has its own page with a definition, how it tends to push price, and 90 days of history — and the position gauge reconstructs its own value from the three knobs that built it, so the trade signal is an audit trail rather than a verdict.
What I'd carry forward
Three things now, where I used to say two. First, point-in-time discipline is worth more than any model: get the data-timing right and a simple model stays honest; get it wrong and a fancy one lies convincingly. Second, write the test that proves the absence of leakage before you write the feature — it quietly changes what you build, and what you let the AI build for you. Third — the lesson this project taught me about my own job — when AI does the building, the product owner's leverage moves to defining "good" and holding the line on it. Claude will clear whatever bar you set; choosing the right bar, and refusing to lower it when a looser one would flatter the results, is the actual work. Chainsight will never beat the market, and that was never the point. It's the most rigorous "toy" I've built — and the rigor is the product.